
(Re)Based Rollups
Extending Ethereum Fork-Choice Rules

Rollup engineering has historically focused on the state-transition function (STF). That STF drives the engineering concerns of the node and the proving system. It holds user balances and contracts, and processes user transactions. We have designed run-ahead sequencers, pre-confs, and other mechanisms to pre-commit to the output of the STF. And we continue to spend effort on Verkle tries and other complex statements about the state it produces. For a change of pace, we’d like to examine an under-explored part of the rollup: its fork-choice rule. Once understood properly, rollup fork-choice rules become more interesting and useful than the state-transition function.

Fork-choice Rules and Reorgs
Fork-choice rules (FCR) describe how blockchain nodes establish confidence in the history of a chain based on subjective1 information. The simplest and best-understood rule is the proof-of-work rule: nodes must accept the history with the most accumulated difficulty.2 Nodes execute the fork-choice rule continuously as they learn consensus-relevant information. Each new block, attestation, or simply the passage of time may cause a node to update their subjective view of the chain tip according to some fork-choice rule.

Fork-choice rules are not objective evaluations of the chain tip. They rely on information that the node has observed, and are therefore always subjective. Nodes cannot enforce their FCRs be followed by other nodes, and at any given time, different nodes on the network may have different outcomes from the same FCR based on their individual subjective inputs. Trivially, this always occurs during block propagation. A block will have been accepted by some nodes, but not yet reached other nodes. As a result, the nodes will be on different histories, both of which are subjectively correct. As nodes observe new information, they update their view of the history according to their fork-choice rule. In a well-designed network (and in the absence of long-term partitions), nodes’ subjective views should converge over time. When nodes have consistent views of a chain’s history, we say they are “in consensus” with each other. Nodes following well-designed FCRs are eventually in consensus with other nodes.3
Ethereum has two officially-recommended fork-choice rules, one of which is also considered a fundamental protocol rule.4 First, attesters and proposers are expected to use a modified version of the LMD-GHOST5 rule to determine the canonical tip. Proposers should base their block on the tip chosen by the LMD-GHOST rule, and attestors should only sign attestations that confirm their subjective tip. Second, nodes are required to use the Casper FFG6 rule to finalize blocks. A node must not accept any history which removes a block after that block has been confirmed by their view of the Casper FFG rule. To conform to Ethereum protocol rules, nodes must follow the Casper FFG rule, but may deviate from the LMD-GHOST rule.7
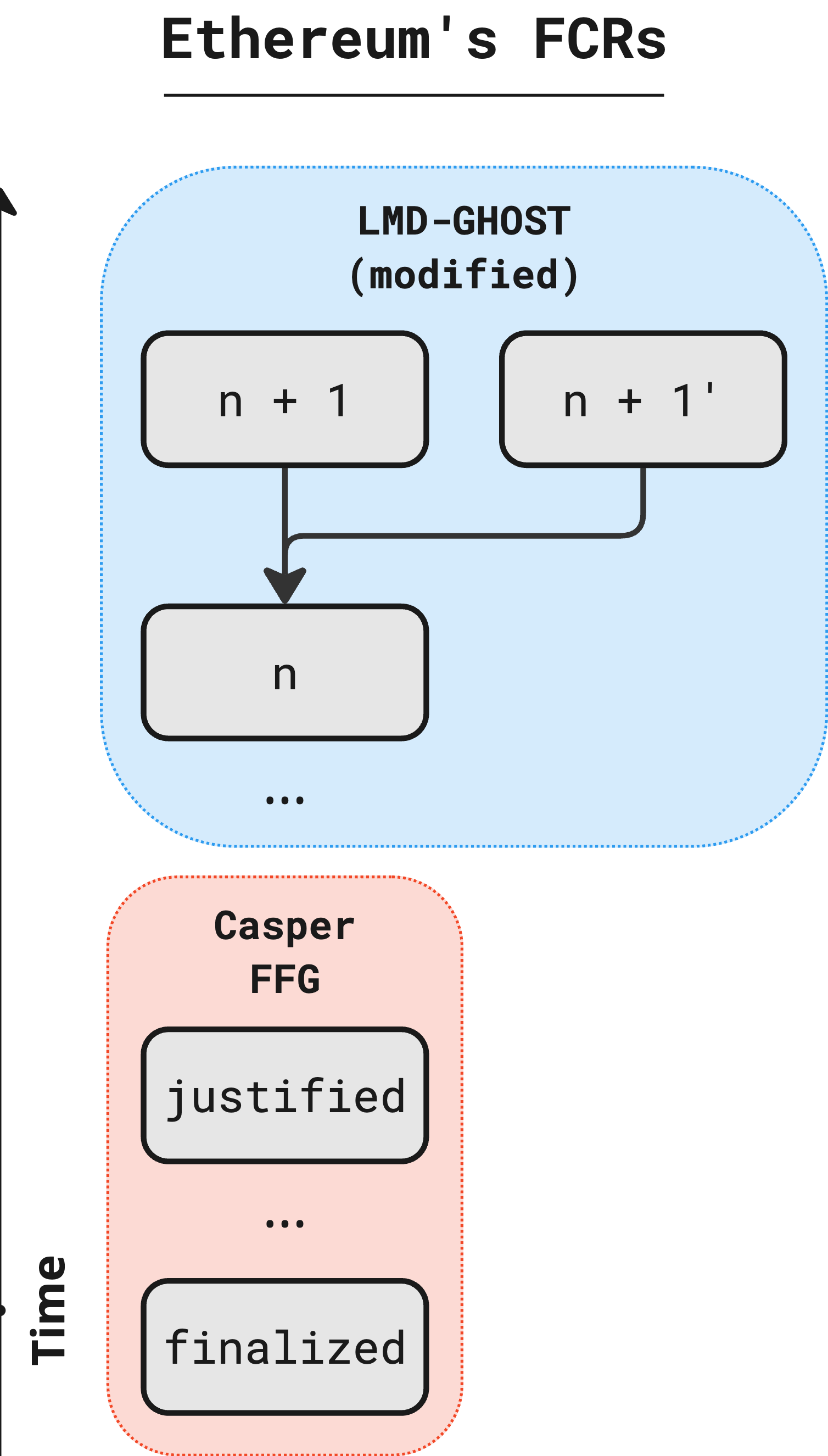
Fork-choice rules allow observers (like nodes) to establish a view of the chain history, and therefore of the chain state. When this view changes in a way that rejects blocks previously accepted a chain reorganization (“reorg”) occurs. Nodes must unwind the execution of the blocks which have been decanonized, and execute blocks which have been canonized. The depth of permitted reorganization falls out of the design of the FCR. Some - like uncheckpointed PoW - allow reorganization of the entire chain, while others - like Tendermint and other “single-slot finality” FCRs - do not allow reorgs at all. While LMD-GHOST allows reorgs of unlimited depth, Casper FFG does not. Casper is mandatory. It is a violation of the protocol rules for a node to revert a block once finalized by its view of the Casper FFG FCR. Therefore rule-following Ethereum nodes currently support reorgs up to that depth.8
Fork-choice rules have a few secondary users. Light clients,9 for example, hypothetically follow an FCR without executing the state-transition function. More interesting, however, are rollups. Rollups, as users of the host chain, must follow some host FCR. Rollups, as chains, also have an FCR. Many desirable properties of a rollup derive from the relationship between host fork-choice and rollup fork-choice.
Reorgs are subjective, because FCRs are subjective. Because nodes have different clocks and views, some nodes may experience reorgs while others do not. For simplification, we say that the network experiences a reorg when a non-trivial fraction of nodes experience a reorg. This frequently removes individual blocks from the accepted history (preventing their Casper justification and eventual finalization), but very rarely removes more than 1 or 2 blocks. A reorg of depth 7 in 2022 was considered notable enough to prompt in-depth exploration. It would take a reorg of >= 32 blocks to remove the Casper-justified block. This should be considered a black swan event, and as a result justification is called “safe” by the node RPC.
Authors’ Note:
Throughout the remainder of this note, when we say “the host reorgs” or “the rollup reorgs” please interpret it to mean “when a significant number of host/rollup nodes accept a new history that is not a strict extension of previously accepted history after evaluating the fork-choice rule.” It is important to remember that reorgs are entirely subjective, but it’s very clunky to always use subjective language.
FCRs in Rollups
Much debate notwithstanding, rollups are blockchains. Their blocks form a neat chain, which nodes use to calculate the current state. Rollups have fork-choice rules. This may be a somewhat controversial statement. We’re too used to modeling rollups as dependent systems. However, it is a necessary consequence of rollups having blocks that form chains. There must be a process by which a node authenticates and accepts a new block. To the extent that the host chain affects the inputs to that process,10 the rollup must resolve history conflicts arising from host reorgs. We’ll first discuss the category containing all existing rollups: Host-following FCRs. We’ll then consider a second category with no concrete examples.
Host-following Fork-choice
All modern rollups are host-following. For host-following rollups, all rollup reorgs are triggered by a host reorg11 (although, this doesn’t mean that host reorgs always cause rollup sequence or state changes - more on this later). Host-following rollups include Arbiturm, Optimism, Taiko, ZkSync, and many others. Existing rollups can be sorted into two general types: Based and Run-ahead.12
Based (Totally host-following)
Based rollups follow the host fork-choice perfectly. For based rollups, every host reorg triggers a re-extraction of the rollup history corresponding to the affected host blocks. The new host history may contain different transactions and orderings, so as rollup nodes observe host reorgs, they re-derive the rollup sequence from the new host history. They then execute the rollup state-transition function on the new sequence to produce the new state,13 and discard the old sequence and state transitions. In this way, each host reorg directly causes a rollup reorg.

Based rollups should be considered totally host following in that there is a bijective relationship: all host reorgs cause a reorg of the rollup, and all rollup reorgs are triggered by a specific host reorg. Based rollups have the simplest relationship to their host. Other systems introduce significant complexity.
Run-ahead (Partially host-following)
Run-ahead14 rollups muddy the fork-choice waters significantly. Run-ahead rollups - like Arbitrum and Optimism - assume that the Sequencer will not equivocate or falsify execution, and leverage this assumption to provide pre-confirmation of inclusion and pre-commitment to execution outcomes. Because the sequence is finalized before it is posted to the host chain, Ethereum reorgs often cannot cause a change to the sequence. The Sequencer’s commitment provides all necessary assurances to nodes that the sequence is immutable.

These run-ahead FCRs simply follow the Sequencer’s signatures, regardless of the host-chain’s behavior. If the new host history omits previously committed rollup sequences, the rollup must reconfirm them, however, this does not imply a rollup reorg unless the sequencer equivocates. In order to support bridge-ins, the Sequencer references a specific host block in their batch commitment. The rollup sequence and the outcome of its state transition cannot change unless the referenced host block is replaced in the post-reorg host chain. Sequencers delay these host commitments for a security margin to ensure that these reorgs are uncommon.15

Compared to a based rollup, the sequence of a run-ahead rollup demands significantly more independence from its host’s FCR. Run-ahead rollup fork-choice rules should be considered partially host-following because all rollup reorgs are triggered by a specific host reorg, but not all host reorgs cause a rollup reorg. Which is to say, there is an injective relationship from rollup reorgs onto host reorgs.
Brief Digression
We discuss based and run-ahead rollups because they exist. We can imagine other examples of totally and partially host-following rollup fork-choice rules that are not strictly based or run-ahead. For example, consider a rollup using a lagging sequencer. In this case the sequencer orders a set of transactions after those transactions have been committed to the host chain. First, users commit transaction data in one epoch. In the next epoch the sequencer chooses an ordering for those transactions, and all nodes execute state-transitions.16 Ordering behavior could be invalidated if the host reorgs deeply enough to change transaction data in the commit epoch, leading to a reorganization of the rollup history. Which is to say, the FCR for this rollup would be partially host-following.
While there has been minimal exploration of rollup FCRs outside of run-ahead and based, at least we can examine some deployed examples of host-following rollups. Another major class of rollup fork-choice rules has not been explored at all.
Host-watching Fork-choice
Host-following fork-choice rules change their output only when the host chain FCR output changes. On the other hand, for host-watching fork-choice, only some rollup reorgs are triggered by a host reorg. Host-watching fork-choice rules have conditions under which the rollup FCR may reorg even though the host fork-choice rule has not reorged.17 This appears counterintuitive. We’re not used to thinking about rollup history as independent of host history. However, this is a host-centric view of the rollup history.
While the rollup history must be derivable from the host history at any given point,18 rollups do not need to guarantee that that history becomes immutable at any point. Rollups have their own FCR. A rollup designer can choose a non-finalizing FCR, and a rollup engineer can write a node that respects such an FCR. There is no reason that rollup FCRs must be host-following. In fact the original Merged Consensus design, from which most modern rollup study descends, has a host-watching fork-choice. The design reorgs the rollup based on the state of the host in addition to the history of the host. Because it relies on contract state to enforce its FCR’s fault proof requirements, there are situations (valid fault proofs) under which the rollup may reorg in the absence of a host reorg.
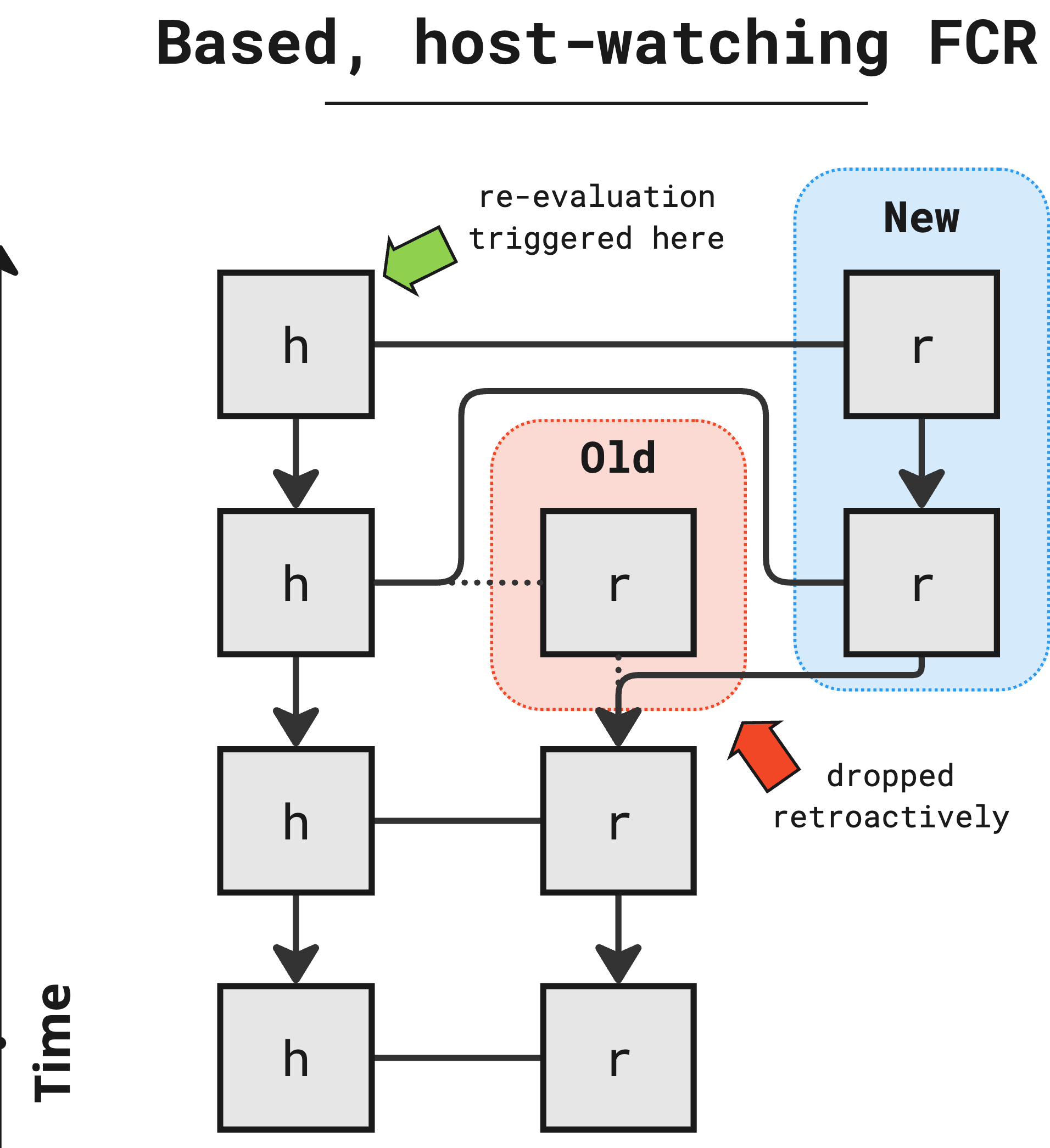
Rollups can leverage reorgs to achieve interesting results. For rollups, updating the FCR means selecting a different sequence. Allowing the rollup to choose a new history effectively means reaching backwards in time to change things that have already occurred. Fork-choice extensions allow the rollup to enforce retrospective rules on its own history, state, and state-transitions. These rules may be evaluated at time t+1, but affect the outcomes of actions that occurred at time t by causing a reorganization of the rollup history.
(Small) Limitations
Like any fork-choice rule, the rollup FCR must rely only on information that the node can observe. In addition, rollups must be fully derivable from the host history. This imposes an additional constraint: rollup FCRs may only read information computable from the host history or state. This ensures that new nodes may still sync the rollup.19 This seems like a serious restriction, however it allows significantly more flexibility than it appears. Anything that can be submitted to host DA or produced by a smart contract can be used by the rollup FCR. This allows oracles, zk or fault proofs of any computation, DEX prices, and NFT ownership to be included in the rollup fork choice rule as long as they pass through the host history and/or state.
In addition, for rollups with bridges to the host chain, the bridge may not pass messages to the host until the rollup FCR has finalized the rollup history to a high degree of confidence. The FCR controls the inputs to the STF, which in turn controls the inputs to the bridge.20 As a result, if the FCR reorganizes the chain history, the bridge may have passed messages that are no longer part of the rollup history. That would be bad. The bridge from rollup to host must choose a subjective FCR and wait for it to be satisfied. This is the same constraint discussed with respect to light client bridges earlier, as ZK-proof and fault-proof bridges are simply a reified light client bridge.21
Examples
Reorganization of rollup history can be used to alter outcomes without altering transaction inclusion. Because the FCR defines the rollup’s history, it is allowed to edit it in any deterministic fashion based on any available information. It can insert arbitrary state transitions, transactions, state changes, hard forks, etc into the rollup’s history, even after many blocks have elapsed. The node must then evaluate the new history.22 The new history does not necessarily have to have any relationship to the old one, as long as it can be deterministically derived from host information. This shines in the presence of enshrined applications.
A simple and obviously useful example would be allowing a permissioned party to retroactively veto specific transactions on the rollup. It would be simple to set up as a specific event emitted by some host contract containing the transaction ID of the transaction to be removed. Upon observing such an event, a rollup node’s FCR would change the rollup’s tip to a new block whose history does not include the specified transaction. The nodes would unwind their local history to just before the transaction’s inclusion, and then re-execute all transactions except the specified transaction. This would allow an oracle to effectively “roll-back” hack transactions or other chain issues without a hard fork.23
Retroactive history changes seem broadly applicable.24 Application-specific rollups, or a general rollup willing to enshrine specific applications, could differentiate from applications hosted on general-purpose rollups by enshrining application semantics in the fork-choice rule. This would allow them to run application logic that extends across many transactions or blocks in ways that cannot be achieved by smart contracts alone.
Followup work
Optimization: Delayed State Commitment
Rollups whose FCR allows for retroactive history changes may want to delay committing to their state until the FCR guarantees finality as is done in other ecosystems.25 Rather than calculating a state root for sequences which may be reverted, they could instead delay calculation of that root until the protocol rules out reorgs. This would save a significant amount of calculation on each reorg,26 allowing deeper reorgs with the same computational resources. However, delayed commitment would marginally delay fault- or zk-proof based bridges. Given the complex trade-offs and that the chief benefit here is optimization, it seems like significant more examination would be warranted.
Multi-host-following/watching Rollups
A rollup has its own fork-choice rule, which it can extend in arbitrary ways. Why not introduce the fork-choice rule of a third chain? This would allow the rollup privileged communication with that chain. This has been loosely explored before and at first appears to create serious synchrony issues. Nodes following independent chains may have completely different views of the FCR outcome for each chain, and those views may diverge forever. However, we can use the same trick as applications to get access to information outside the host. We can simply pass information through the host.
Rather than watch the third chain directly, we can introduce an evaluation of the third chain’s FCR into the host chain’s state or history via a smart contract. The rollup FCR can read the result of this smart contract execution. In this way, the rollup’s FCR has access to any bridge which the host chain has access to. While this seems to solve the problem, it does introduce some amount of time lag. The delay to communicate to the rollup from the third chain is increased by the finalization period of the host bridge’s FCR for the third-chain.27 This feels bad. There may be ways to improve this without integrating the third chain’s FCR into the host FCR. It may be possible to use contingent states or some other local-verification solution to speed this up and prevent the wait. More research is needed.
Conclusion
Rollups are real blockchains. They have their own nodes, fork-choice, and state. Rollups can reach backwards in time and edit their own history and state. By carefully choosing their fork-choice rules rollups can achieve fast communication with the host and allow their applications to modify the history of the chain in useful ways. There are clear use cases for FCR-enshrined applications for hack-reversion, censorship, and fair execution guarantees. Rollup FCR research has been chilled by the over-complex design of run-ahead sequencing and the over-simplistic design of based sequencing. Rollups using run-ahead or based sequencing are giving up a significant edge over competitors.
Read “observable”.
This is often incorrectly called the “longest chain” rule. Even Satoshi made this mistake.
With the usual hand-waving about weak subjectivity and limitations on network partitions.
In-depth explanation of these rules is outside the scope of this note. People looking to learn more should consult The Book.
“Latest-Message-Driven Greedy Heaviest-Observed Subtree”, a modified version of GHOST. Ethereum sometimes modifies its LMD-GHOST implementation in response to observed defects.
“Friendly Finality Gadget”. It’s a joke about Casper the Friendly Ghost.
There’s significant nuance here. We do not recommend nodes begin using custom FCRs, and doing so might be considered “unaligned”.
Casper FFG also includes the concept of a “justified” block, which is an output of the Casper FFG FCR that is used as an input to the recommended LMD-GHOST FCR. Assuming nodes use the justified block as input to the LMD-GHOST process and honestly attest and propose based on the LMD-GHOST output, the justified block will eventually be finalized.
And bridges as a special class of light client. A bridge must choose an FCR and wait for safety according to that FCR before allowing any messages sent by the tracked chain to be received by the target chain. The selection of this FCR is critical. The bridge’s FCR must achieve a high level of confidence that the tracked chain’s FCR does not allow rejection of blocks that the bridge’s FCR has accepted. This would result in reversion of messages from the tracked chain after they had been delivered to the target chain. That’s bad.
This is a bit of a rhetorical device. A rollup must be completely derivable from its host in retrospect, i.e. the host perfectly determines the inputs to the FCR for any newly syncing node, although not necessarily for nodes that are actively following the tip. In other words the host chain’s effect on the inputs to the rollup block-acceptance process is total for newly syncing nodes.
This is equivalent to saying that a change in the rollup fork-choice rule omits previously-committed sequences only when a change in the host chain fork-choice rule omits previously-committed blocks. This is a subtle but important definition and is difficult to state more simply. For host-following rollups, appending a host block without reverting one never results in the rollup reverting some sequence.
The design space allows for more interesting types of host-following rollup. One can imagine permissioned based rollups, multi-sequencer run-ahead systems, etc etc.
There’s an interesting bit of nuance here, since based rollups strive to be derivable entirely from their own sequence, i.e. to have no data dependency on the host state in the blocks that contain the sequence. This is achievable for environmental attributes like the block timestamp, but not achievable while still allowing bridging into the rollup. Bridge-ins to the rollup are contained in the host state, and may change during reorgs. As a result, the rollup must re-evaluate its state-transition based on host state in reorgs, or eschew bridge-ins, which seems bad.
As opposed to a “based” sequencer model. In most modern rollups the sequencer “runs ahead” of Ethereum as it provides inclusion and execution attestations for a transaction before the transaction has been committed to Ethereum. In this model the Sequencer has total control over the sequence, and the outcome of the transaction must be independent of Ethereum reorgs.
For example, Arbitrum’s sequencer references justified blocks, implying a delay of about 13 minutes, while Optimism’s sequencer wait’s 1-3 minutes. Both choose to delay forced inclusion transactions significantly longer than the expected finalization time of Ethereum. Although Casper FFG allows finalization to be delayed indefinitely, and reorgs can hypothetically reach any depth, this is vanishingly unlikely to occur in practice and can be discounted by users.
The rollup could be running each execution epoch simultaneously with the next commitment epoch rather than alternating between them.
This is a subtle but important definition and is difficult to state more simply. It is equivalent to saying that the rollup may omit previously-committed data even when the host has not omitted previously-committed blocks. For host-watching rollups, appending a host block may result in the rollup reverting some sequence.
Or at least eventually-derivable in the case of run-ahead FCRs
If a rollup FCR includes information that is not derived from the host, it is not a rollup.
There is a common misconception about fault proofs, that the fault proof “reorgs” the rollup. In reality, the rollup FCR is executed long before the fault proof, and the fault proof cannot be constructed before the FCR is executed (and therefore can never be an element of the FCR as that would create a cyclic data dependency). In other words, the ordering is an output of the FCR, and an input to the fault proof. As a result, the fault proof cannot ever be an input to the FCR.
They are interesting as a special class of light client bridge that evaluates both FCR and STF outputs. This is distinct from almost all other light client bridges, which validate only the FCR and only in a limited way. Rollup bridges may achieve this because the history and state are deterministically calculated from information committed to the host. Host-watching FCRs with arbitrary behavior do not prevent proof-based bridges, however they do increase the complexity.
This imposes practical constraints. Nodes must re-execute blocks to derive the new state. So reorging to a depth of 500 blocks requires processing 500 blocks again.
An extension of this could couple the oracle-driven FCR update with an irregular state transition that preserves account nonces, effectively invalidating all transactions that occurred during the reverted period. This would prevent knock-on effects of the hack, by ensuring that all transactions ma
Imagine a rollup whose fork-choice rule observes the MakerDAO oracle and retroactively changes the outcomes of trades that deviate too far from that price. And consider an AMM whose LPs can retroactively cause themselves to have left or joined the pool at earlier points in history. Are these good ideas? Maybe not. But they are possible, fairly easily achievable and indicative of how much power the fork-choice rule wields.
Tendermint-based chains have a 1 block delay in state calculation and commitment. It has complex ramifications.
Anecdotally, state-trie calculation takes up >50% of block execution time.
This is a complicated sentence. The host bridge observes the third chain via some FCR implemented in the smart contract. This FCR has some finalization delay before reading from it is safe. Reading unsafe data may result in receiving fraudulent messages. As a result, the rollup needs to wait for the host contract’s enshrined FCR’s view of the chain to reach acceptable finality.